 PerceptionDLM
PerceptionDLM
Parallel Region Perception with Multimodal Diffusion Language Models
Peking University MSALab · ByteDance
News
- 📌 PerceptionDLM is the first model to achieve parallel region captioning and perception by leveraging the parallel decoding nature of diffusion language models. If you find our work useful, please consider giving our GitHub repository a star and citing our paper 🙏
- [2026-06] We release the model weights, training data, and ParaDLC-Bench!
- [2026-06] We release the PerceptionDLM paper on arXiv and the codebase!
Abstract
Multimodal large language models (MLLMs) have achieved remarkable progress in visual understanding tasks. However, most existing MLLMs rely on autoregressive generation, which limits their efficiency for perception tasks that require captioning multiple regions. In this work, we propose PerceptionDLM, a multimodal diffusion language model optimized for efficient parallel region perception. Built upon PerceptionDLM-Base, a strong foundational baseline that achieves state-of-the-art performance among open-source diffusion MLLMs, our architecture fully leverages the parallel decoding nature of diffusion language models (DLMs). Specifically, we introduce efficient prompting and structured attention masking to enable simultaneous perception of multiple masked regions, allowing the model to generate region descriptions in parallel at both the sequence and token levels. To systematically evaluate the parallelism property of visual perception capability for DLMs, we construct a new Parallel Detailed Localized Captioning Benchmark (ParaDLC-Bench) by scaling DLC-Bench to include multiple region masks per image, enabling joint evaluation of both caption quality and inference efficiency. Experiments demonstrate that PerceptionDLM maintains competitive performance in region captioning while achieving substantial speed improvements for multi-region perception. To the best of our knowledge, we are the first to achieve parallel region captioning and perception by leveraging the advantages of diffusion language models. Code, models, and datasets are released.
Model Architecture
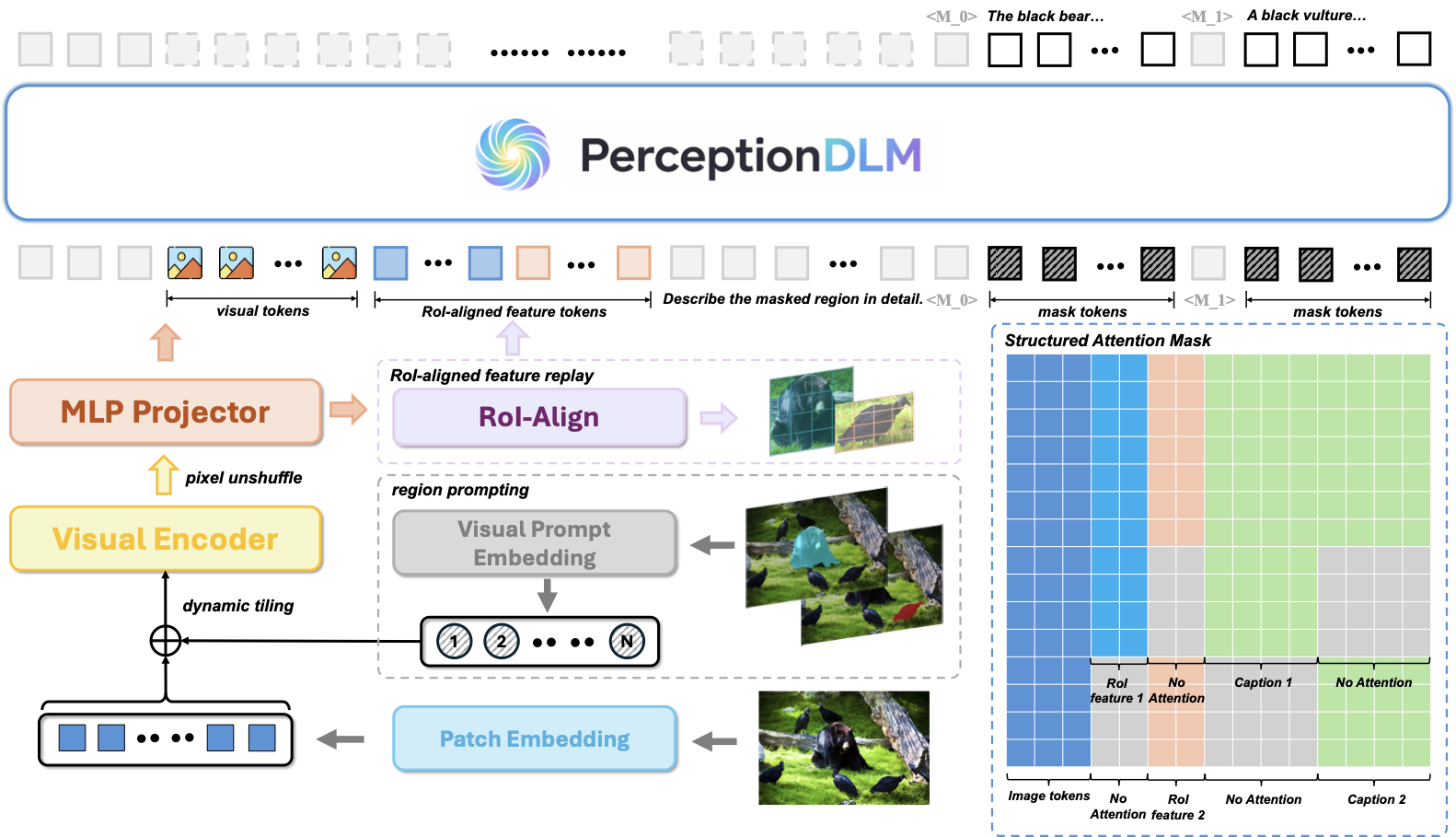
Overall Architecture of PerceptionDLM. Given an image and multiple region masks, the model perceives and describes all regions within a single denoising process via efficient prompting and structured attention masking.
PerceptionDLM couples a visual encoder with a discrete diffusion language model (LLaDA-8B-Instruct backbone). Instead of decoding region descriptions one-by-one like autoregressive captioners, it exploits the parallel decoding nature of DLMs through two key designs:
- (1) Efficient parallel prompting. Multiple masked regions are packed into a single prompt so that all region descriptions are generated simultaneously in one denoising pass, avoiding the linear latency growth of sequential region captioning.
- (2) Structured attention masking. A carefully designed attention mask isolates each region's generation stream while sharing the global image context, enabling parallelism at both the sequence and token levels without cross-region interference.
- (3) Strong diffusion VLM baseline. PerceptionDLM-Base, trained with a multi-stage recipe, outperforms LLaDA-V on 15/16 multimodal benchmarks, providing a solid foundation for parallel region perception.
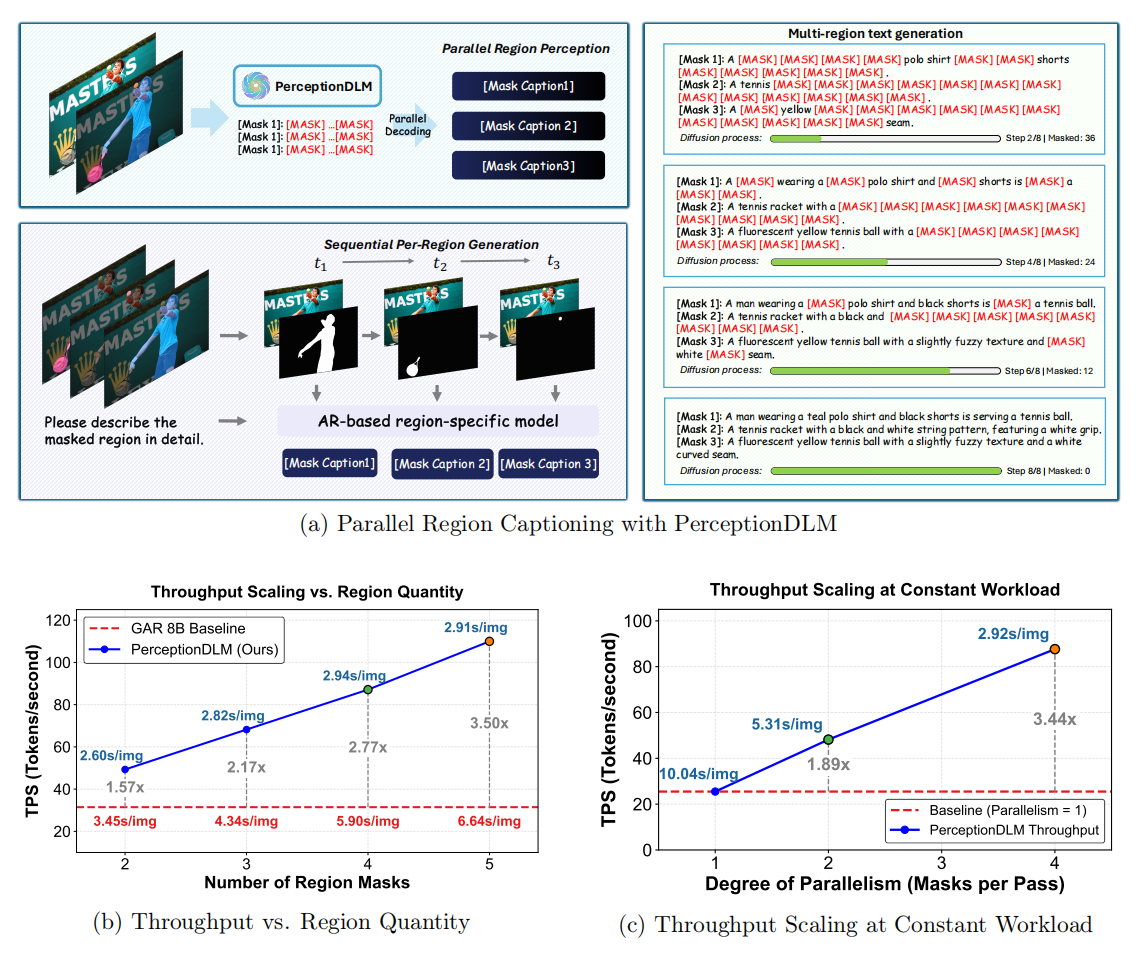
Parallel Decoding Demos
Given multiple region masks, PerceptionDLM generates descriptions for all regions in parallel within a single denoising process — visualized below as tokens being filled in simultaneously across regions.
Parallel region captioning — example 1
Parallel region captioning — example 2




Main Results
PerceptionDLM-Base — Multimodal Understanding
PerceptionDLM-Base establishes a strong open diffusion VLM baseline, outperforming LLaDA-V on 15/16 benchmarks and staying competitive with leading AR VLMs (Qwen2.5-VL, InternVL3) at the same scale.
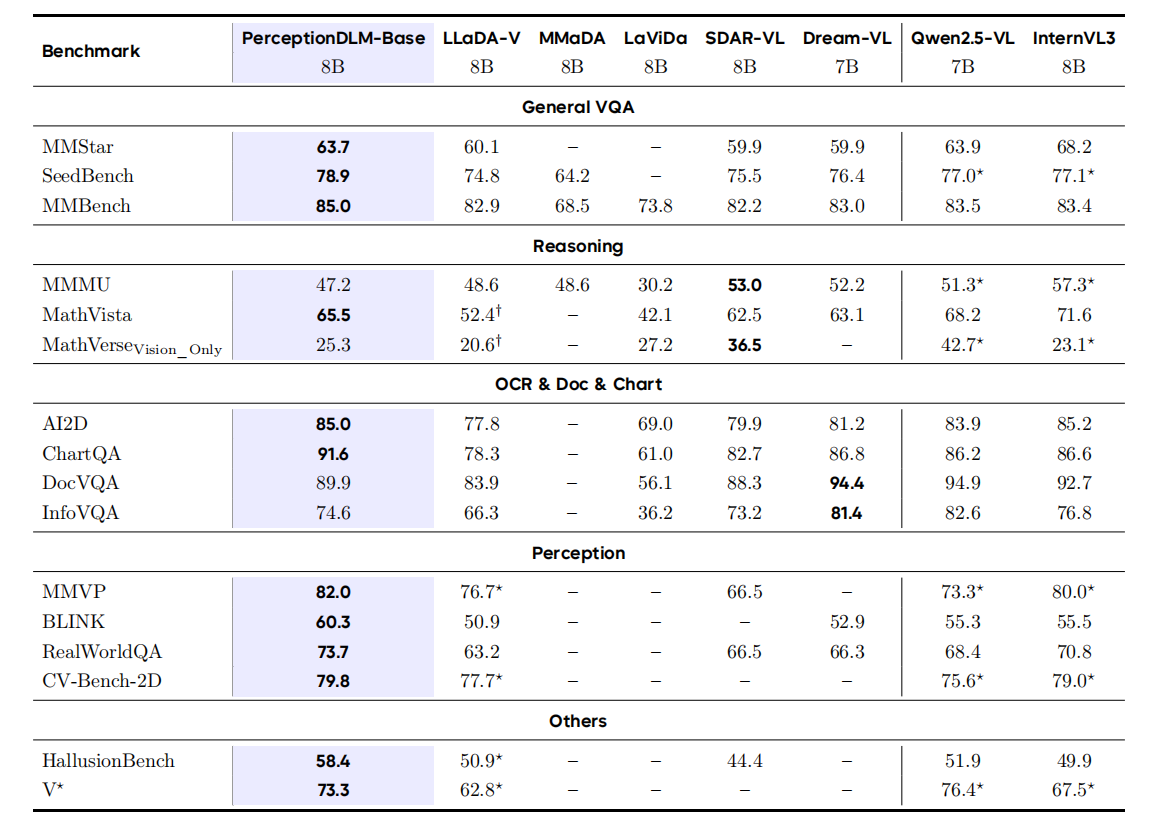
Evaluation comparison across vision-language models on multimodal understanding benchmarks. Bold = best score in each row; †/★ = re-evaluated by us (official scripts / VLMEvalKit).
PerceptionDLM — Parallel Region Perception (ParaDLC-Bench)
PerceptionDLM achieves a strong accuracy–efficiency trade-off on multi-region dense captioning, decoding multiple regions per forward pass for substantial speedups.
| Method | Type | ParaDLC-Bench Avg (%) | TPF ↑ | Time (s) ↓ |
|---|---|---|---|---|
| GAR-8B | AR (sequential) | 69.5 | 1.0 | 479 |
| LLaDA-V-8B | Diffusion | 35.2 | 1.0 | 3241 |
| PerceptionDLM-8B | Diffusion (parallel) | 62.4 | 2.9 | 276 |
TPF = Tokens Per Forward (higher means more parallel). Full tables and the complete evaluation protocol are reported in the paper.
BibTeX
If you found this work useful, please consider citing our paper as follows:
PerceptionDLM
@article{sun2026perceptiondlm,
title = {PerceptionDLM: Parallel Region Perception with Multimodal Diffusion Language Models},
author = {Sun, Yueyi and Wang, Yuhao and Li, Jason and Tian, Ye and Zhang, Tao and Mai, Jacky and Wang, Yihan and Wang, Haochen and Bai, Jinbin and Yang, Ling and Tong, Yunhai},
journal = {arXiv preprint arXiv:2606.19534},
year = {2026}
}