Abstract
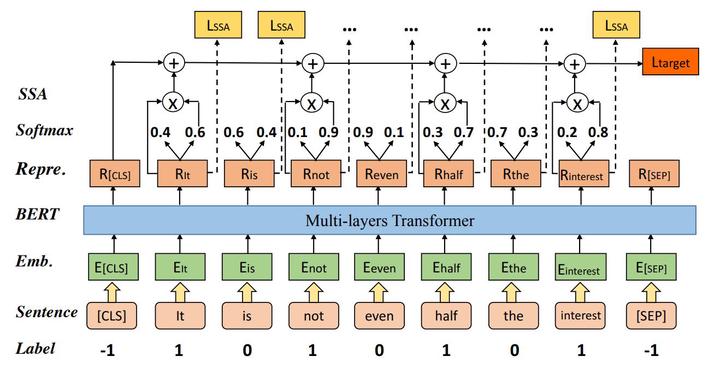
One of the most popular paradigms of applying large pre-trained NLP models such as BERT is to fine-tune it on a smaller dataset. However, one challenge remains as the fine-tuned model often overfits on smaller datasets. A symptom of this phenomenon is that irrelevant or misleading words in the sentence, which are easy to understand for human beings, can substantially degrade the performance of these fine-tuned BERT models. In this paper, we propose a novel technique, called Self-Supervised Attention (SSA) to help facilitate this generalization challenge. Specifically, SSA automatically generates weak, token-level attention labels iteratively by probing the fine-tuned model from the previous iteration. We investigate two different ways of integrating SSA into BERT and propose a hybrid approach to combine their benefits. Empirically, through a variety of public datasets, we illustrate significant performance improvement using our SSA-enhanced BERT model.